Understanding our Deep Learning Application
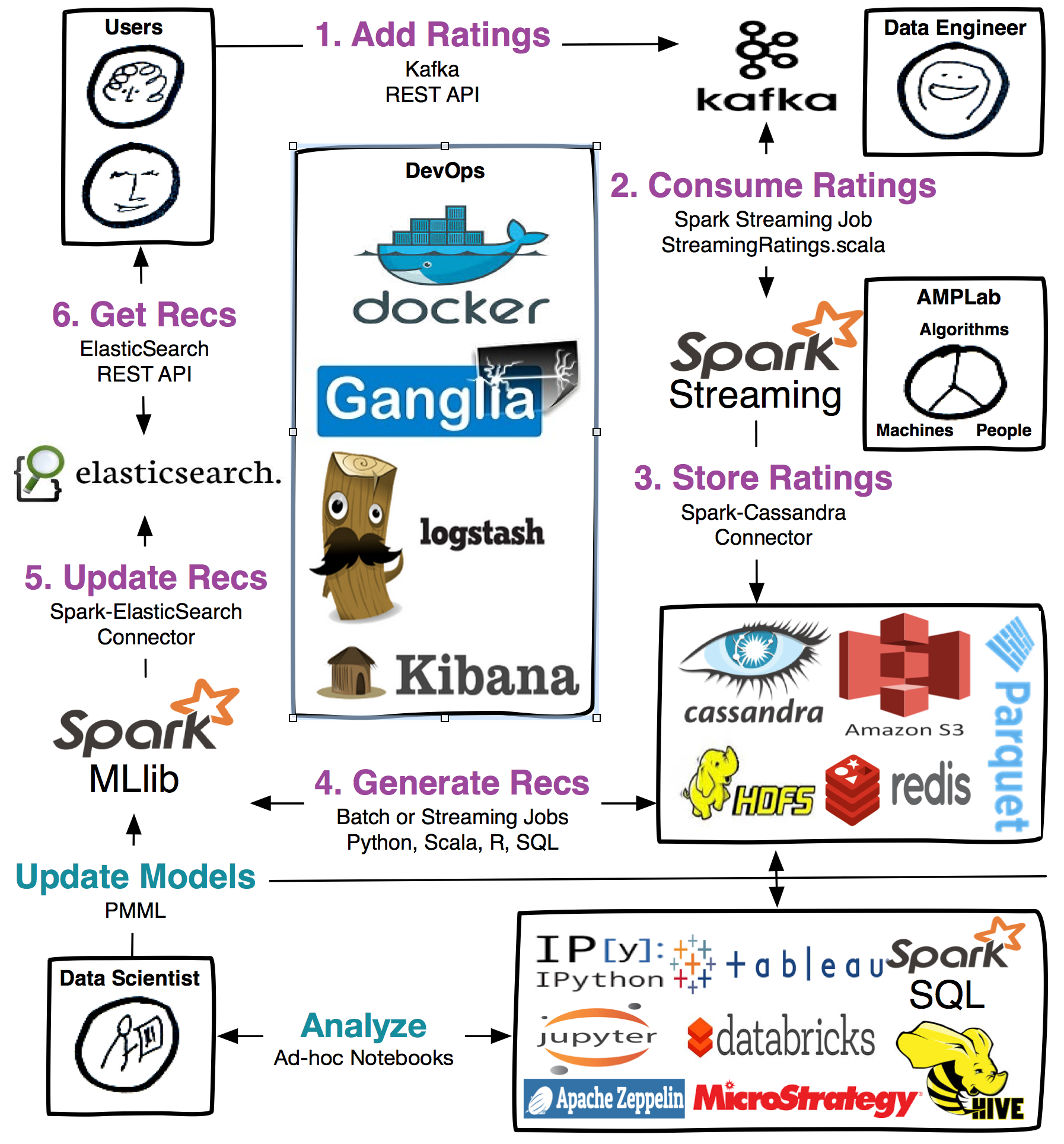

Real-time Payment Risk Mitigation Engine
In this book, we want to build the world’s most trusted real-time mobile payment risk estimation engine. Mobile payment clients will trust us to connect them with world-class payment gateway hosts for hassle free payment experiences. Correspondingly payment system hosts trust that guests will treat their home with the same care and respect that they would their own. Thus the payment risk estimation system helps users earn this trust through positive payment interactions, and the user ecosystem as a whole prospers. The overwhelming majority of mobile payment users act in good faith, but unfortunately, there exists a small number of bad actors who don’t. The payment risk team will works across many disciplines to help protect users from these bad actors, ideally before they have the opportunity to impart negativity on the community. There are many different kinds of risk that online businesses may have to protect against, with varying exposure depending on the particular business. Payments companies deal a lot with credit card chargebacks. It is possible to mitigate the potential for bad payment actors in different ways. 1) Product changes Many security risks can be mitigated through user-facing changes to the product that require additional verification from the user. For example, requiring email confirmation, or implementing 2FA to combat account takeovers, as many banks have done. 2) Anomaly detection Scripted attacks are often associated with a noticeable increase in some measurable metric over a short period of time. For example, a sudden 1000% increase in usage in a particular city could be a result of excellent marketing, or fraud. 3) Simple heuristics or a machine learning model based on a number of different variables Fraudulent/Risky actors often exhibit repetitive patterns. As we recognize these patterns, we can apply heuristics to predict when they are about to occur again, and help stop them. For complex, evolving fraud vectors, heuristics eventually become too complicated and therefore unwieldy. In such cases, we turn to machine learning, which will be the focus of this chapter. For a more detailed look at other aspects of online risk management, check out Ohad Samet’s great ebook. Machine Learning Architecture Different risk vectors can require different architectures. For example, some risk vectors are not time critical, but require computationally intensive techniques to detect. Offline architecture is best suited for this kind of detection. For the purposes of this chapter, we are focusing on risks requiring realtime or near-realtime action. From a broad perspective, a machine-learning pipeline for these kinds of risk must balance two important goals:
- The framework must be fast and robust. That is, we should experience essentially zero downtime and the model scoring framework should provide instant feedback. Bad actors can take advantage of a slow or buggy framework by scripting many simultaneous attacks, or by launching a steady stream of relatively naive attacks, knowing that eventually an unplanned outage will provide an opening. Our framework must make decisions in near real-time, and our choice of a model should never be limited by the speed of scoring or deriving features.
- The framework must be agile. Since fraud vectors constantly morph, new models and features must be tested and pushed into production quickly. The model-building pipeline must be flexible to allow data scientists and engineers to remain unconstrained in terms of how they solve problems. These may seem like competing goals, since optimizing for realtime calculations during a web transaction creates a focus on speed and reliability, whereas optimizing for model building and iteration creates more of a focus on flexibility. Engineering and data teams need to work closely together to develop a framework that accommodates both goals: a fast, robust scoring framework with an agile model-building pipeline.
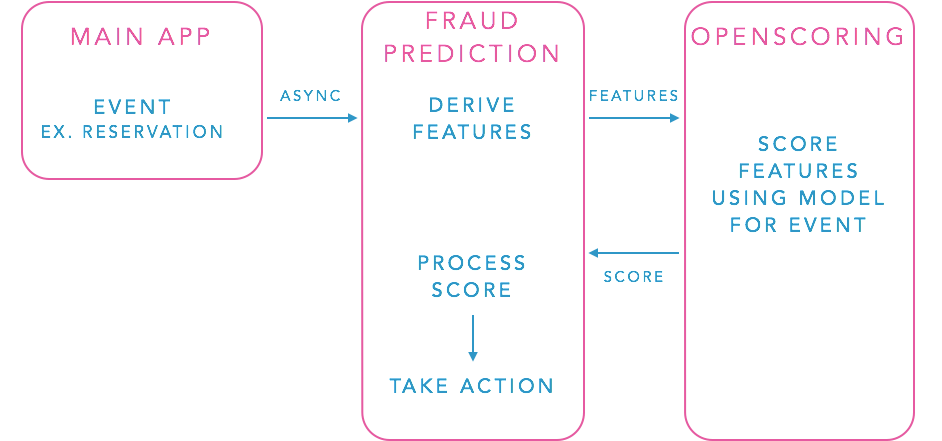
In keeping with our micro-services architecture, we built a separate fraud prediction service to handle deriving all the features for a particular model. When a critical event occurs in our system, e.g., a payment is created, we query the payment risk prediction service for this event. This service can then calculate all the features for the “payment creation” model, and send these features to our OpenRiskscoring service, which is described in more detail below. The OpenRiskScoring service returns a score and a decision based on a threshold we’ve set, and the risk prediction service can then use this information to take action (i.e., put the payment on hold). The risk prediction service has to be fast, to ensure that we are taking action on suspicious events in near real-time. Like many of our back end services for which performance is critical, it is built in java, and we parallelize the queries necessary for feature generation. However, we also want the freedom to occasionally do some heavy computation in deriving features, so we run it asynchronously so that we are never blocking for payments, etc. This asynchronous model works for many situations where a few seconds of delay in payment risk detection has no negative effect. Its worth noting, however, that there are cases where you may want to react in real-time to block transactions, in which case a synchronous query and precomputed features may be necessary. This service is built in a very modular way, and exposes an internal restful API, making adding new events and models easy.
Openscoring Openscoring is a Java service that provides a JSON REST interface to the Java Predictive Model Markup Language (PMML) evaluator JPMML. Both JPMML and Openscoring are open source projects released under the Apache 2.0 license and authored by Villu Ruusmann (edit – the most recent versionis licensed the under AGPL 3.0) . The JPMML backend of Openscoring consumes PMML, an xml markup language that encodes several common types of machine learning models, including tree models, logit models, SVMs and neural networks. We have streamlined Openscoring for a production environment by adding several features, including kafka logging and statsd monitoring. Andy Kramolisch has modified Openscoring to permit using several models simultaneously. As described below, there are several considerations that we weighed carefully before moving forward with Openscoring: Advantages • Openscoring is opensource - this has allowed us to customize Openscoring to suit our specific needs. • Supports random forests - we tested a few different learning methods and found that random forests had an appropriate precision-recall for our purposes. • Fast and robust - after load testing our setup, we found that most responses took under 10ms. • Multiple models - after adding our customizations, Openscoring allows us to run many models simultaneously. • PMML format - PMML allows analysts and engineers to use any compatible machine learning package (R, Python, Java, etc.) they are most comfortable with to build models. The same PMML file can be used with pattern to perform large-scale distributed model evaluation in batch via cascading. Disadvantages • PMML doesn’t support some types of models - PMML only supports relatively standard ML models; therefore, we can’t productionize bleeding-edge models or implement significant modifications to standard models. • No native support for online learning - models cannot train themselves on-the-fly. A secondary mechanism needs to be in place to automatically account for new ground truth. • Rudimentary error handling - PMML is difficult to debug. Editing the xml file by hand is a risky endeavor. This task is best left to the software packages, so long as they support the requisite features. JPMML is known to return relatively cryptic error messages when the PMML is invalid. After considering all of these factors, we decided that Openscoring best satisfied our two-pronged goal of having a fast and robust, yet flexible machine learning framework.
Model Building Pipeline

A schematic of our model-building pipeline using PMML is illustrated above. The first step involves deriving features from the data stored on the site. Since the combination of features that gives the optimal signal is constantly changing, we store the features in a json format, which allows us to generalize the process of loading and transforming features, based on their names and types. We then transform the raw features through bucketing or binning values, and replacing missing values with reasonable estimates to improve signal. We also remove features that are shown to be statistically unimportant from our dataset. While we omit most of the details regarding how we perform these transformations for brevity here, it is important to recognize that these steps take a significant amount of time and care. We then use our transformed features to train and cross-validate the model using our favorite PMML-compatible machine learning library, and upload the PMML model to Openscoring. The final model is tested and then used for decision-making if it becomes the best performer. The model-training step can be performed in any language with a library that outputs PMML. One commonly used and well-supported library is the R PMML package. As illustrated below, generating a PMML with R requires very little code.
This R script has the advantage of simplicity, and a script similar to this is a great way to start building PMMLs and to get a first model into production. In the long run, however, a setup like this has some disadvantages. First, our script requires that we perform feature transformation as a pre-processing step, and therefore we have add these transformation instructions to the PMML by editing it afterwards. The R PMML package supports many PMML transformations and data manipulations, but it is far from universal. We deploy the model as a separate step — post model-training — and so we have to manually test it for validity, which can be a time-consuming process. Yet another disadvantage of R is that the implementation of the PMML exporter is somewhat slow for a random forest model with many features and many trees. However, we’ve found that simply re-writing the export function in C++ decreases run time by a factor of 10,000, from a few days to a few seconds. We can get around the drawbacks of R while maintaining its advantages by building a pipeline based on Python and scikit-learn. Scikit-learn is a Python package that supports many standard machine learning models, and includes helpful utilities for validating models and performing feature transformations. We find that Python is a more natural language than R for ad-hoc data manipulation and feature extraction. We automate the process of feature extraction based on a set of rules encoded in the names and types of variables in the features json; thus, new features can be incorporated into the model pipeline with no changes to the existing code. Deployment and testing can also be performed automatically in Python by using its standard network libraries to interface with Openscoring. Standard model performance tests (precision recall, ROC curves, etc.) are carried out using sklearn’s built-in capabilities. Sklearn does not support PMML export out of the box, so have written an in-house exporter for particular sklearn classifiers. When the PMML file is uploaded to Openscoring, it is automatically tested for correspondence with the scikit-learn model it represents. Because feature-transformation, model building, model validation, deployment and testing are all carried out in a single script, a data scientist or engineer is able to quickly iterate on a model based on new features or more recent data, and then rapidly deploy the new model into production.
Takeaways: ground truth > features > algorithm choice
Although this section has focused mostly on our architecture and model building pipeline, the truth is that much of our time has been spent elsewhere. The process is very successful for some models, but for others we can encounter poor precision-recall. Initially we considered whether we were experiencing a bias or a variance problem, and tried using more data and more features. However, after finding no improvement, we started digging deeper into the data, and found that the problem was that our ground truth was not accurate.
Consider chargebacks as an example. A chargeback can be “Not As Described (NAD)” or “Fraud” (this is a simplification), and grouping both types of chargebacks together for a single model would be a bad idea because legitimate users can file NAD chargebacks. This is an easy problem to resolve, and not one we actually had (agents categorize chargebacks as part of our workflow); however, there are other types of attacks where distinguishing legitimate activity from illegitimate is more subtle, and necessitated the creation of new data stores and logging pipelines.
Most people who’ve worked in machine learning will find this obvious, but it’s worth re-stressing: If your ground truth is inaccurate, you’ve already set an upper limit to how good your precision and recall can be. If your ground truth is grossly inaccurate, that upper limit is pretty low. Towards this end, sometimes you don’t know what data you’re going to need until you’ve seen a new payment scenario, especially if you haven’t worked in the risk space before, or have worked in the risk space but only in a different sector. So the best advice we can offer in this case is to log everything. Throw it all in HDFS, whether you need it now or not. In the future, you can always use this data to backfill new data stores if you find it useful. This can be invaluable in responding to a new attack vector.
Future Outlook Although our current ML pipeline uses scikit-learn and Openscoring, our system is constantly evolving. Our current setup is a function of the stage of the company and the amount of resources, both in terms of personnel and data, that are currently available. Smaller companies may only have a few ML models in production and a small number of analysts, and can take time to manually curate data and train the model in many non-standardized steps. Larger companies might have many, many models and require a high degree of automation, and get a sizable boost from online training. A unique challenge of working at a hyper-growth company is that landscape fundamentally changes year-over-year, and pipelines need to adjust to account for this. As our data and logging pipelines improve, investing in improved learning algorithms will become more worthwhile, and we will likely shift to testing new algorithms, incorporating online learning, and expanding on our model building framework to support larger data sets. Additionally, some of the most important opportunities to improve our models are based on insights into our unique data, feature selection, and other aspects our risk systems